ReRank 算法的核心作用是透過更複雜的相關性判斷機制(例如基於深度學習的模型),通常採用 Cross-Encoder 深度學習模型,對由 Embeddings 模型初步檢索出的 top-k 結果進行精細排序,從而大幅提升檢索結果的準確性和相關性。
Cross-Encoder 是一種BERT架構,主要用於自然語言處理中的文本匹配與相關性評估任務。它的特點是:
輸入是「查詢 (query)」和「文檔 (document)」兩段文字的拼接(範例如下),作為一個整體送入模型做聯合編碼(而非分別獨立編碼)。
[CLS](Classification Token) 是一個特殊的標記,放在輸入序列的最前面,代表整個序列的摘要特徵。模型會將其最後一層的向量表示用作整個序列的語義表示,常用於分類任務或計算序列的整體語義。
[SEP](Separator Token) 是用來分隔兩個句子或段落的特殊標記,幫助模型理解序列中句子邊界。當輸入包含多句子時,[SEP] 用於分隔它們;對於單句子輸入,[SEP] 也會放在句子末尾表示結束。
# 查詢 # 文檔
[CLS] \text{query} [SEP] \text{document} [SEP]
模型利用自注意力機制,深入計算兩段文字之間的交互關係,捕捉細粒度的語義相似度。
經過模型計算後,輸出一個相關性分數(通常是通過分類器輸出 logits,再通過 Sigmoid 轉成概率),表示查詢和文檔的匹配程度。
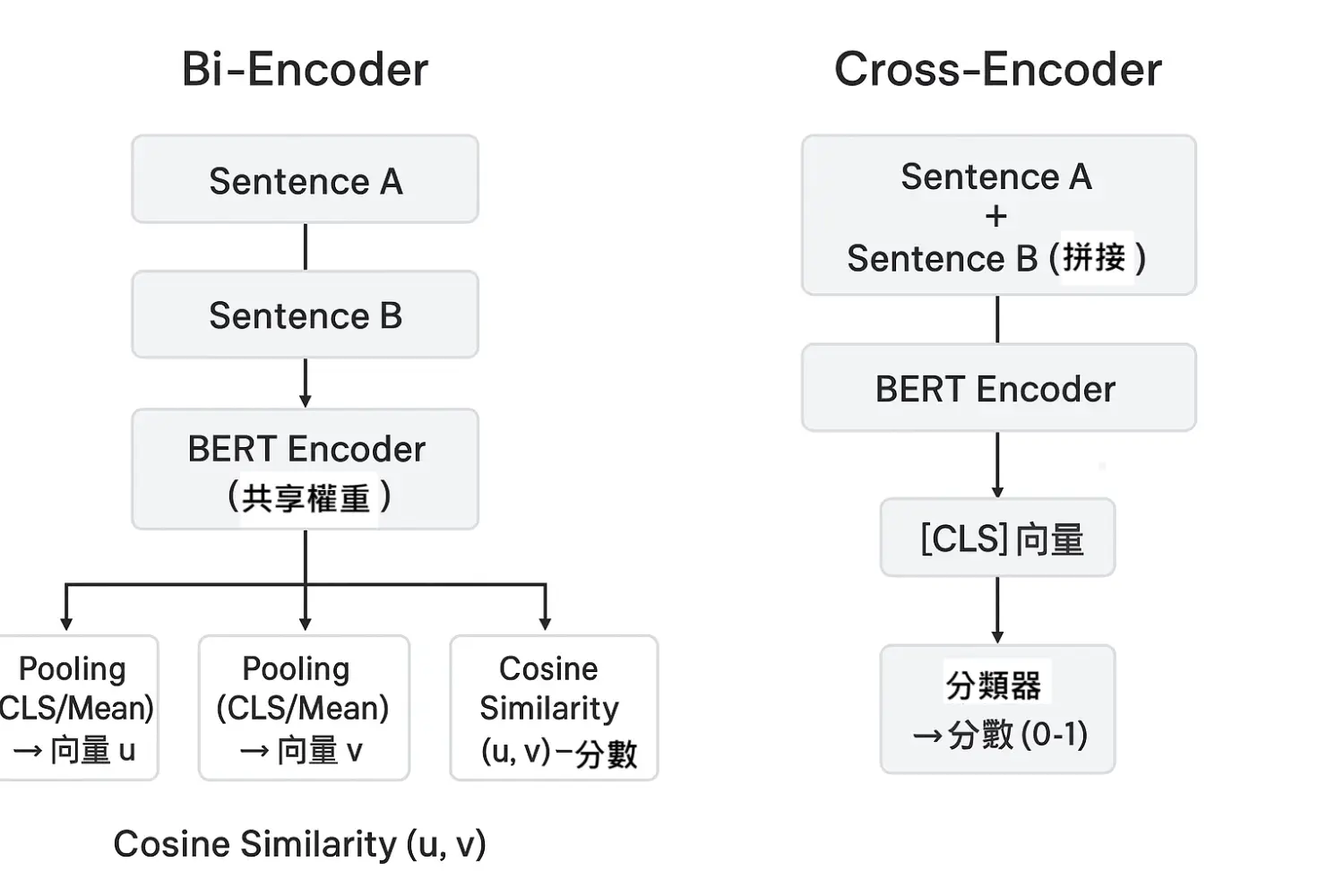
與 Bi-Encoder(或 Embedding 模型)相比,Cross-Encoder 的優點是能精確判斷文本對細節的相似性,但缺點是運算速度較慢,無法預先計算獨立向量,只能在查詢時逐對計算。
在 Cross-Encoder 模型中,會將一段查詢(query)和一段相關文檔(document)合併為一個輸入序列,格式通常是:
顯著提升準確率:
即使是較弱的 Embedding 模型(如 OpenAI small),在搭配top-k 設定為 100 的 ReRanker 進行二階段檢索後,在此篇實測繁體中文檢索的文章中命中率也能達到 98% 以上,超越所有單純使用 Embedding 模型的一階段檢索。
• 具體模型表現:
在繁體中文環境的評測中,ReRank 模型的性能排名大致為:
Voyage > bge-m3 > Cohere > Jina。
◦ Voyage Re-ranker:
表現出驚人的準確率,搭配 voyage-multilingual-2 Embedding 模型,命中率可提升至 99.88%。
◦ 開源 bge 系列:
bge-reranker-m3 在有 A100 GPU 的情況下速度較快。
• top-k 值的影響:
第一階段檢索的 top-k 值越大,最終重排結果越好。如果文件 chunk 大小為 500 tokens,建議使用 top-k 100;若為 1000 tokens,可選 top-k 50,以充分發揮 ReRanker 的優勢。來源
• LLM-based Ranker:
直接使用大型語言模型(LLM)透過 prompt 進行重排(如 RankGPT 或 gpt-4o-mini)在 top-k 10 的情況下,評測結果「還不差」。LLM 的語義理解和泛化能力可能更強,但其輸出穩定性有待提升。來源
• 普遍較高:
ReRanker 模型的執行速度通常較慢,且成本較高。不同於 Embedding 模型主要在前期索引階段產生費用,ReRanker 模型的 API 呼叫成本發生在後期使用者查詢時。
• 計價方式差異:
◦ 按 Token 計價:
Voyage (USD 0.05 per 1M tokens) 和 Jina (USD 0.02 per 1M tokens) 採用這種方式,在文件 chunk 較小或 top-k 值較小時,可能更具彈性與節省空間。例如,Voyage 若 chunk 為 500 tokens 且 top-k 100,單次重排費用約為 0.08 台幣。
◦ 按呼叫次數計價:
Cohere API 的計價方式為每 1000 次呼叫 USD $2。這意味著在每次呼叫中處理更多文件(例如 top-k 100),可能更具成本效益,因為每次呼叫的價格固定。
• 成本權衡公式:
當文件 chunk 的 tokens 數乘以 top-k 超過 4 萬時,選擇 Cohere 可能較便宜;反之則選擇 Voyage 較便宜。
• 開源模型部署成本:
開源 ReRanker 模型(如 bge 系列)若要達到可接受的速度,需要部署 GPU,例如 A100 甚至 H100,這會產生額外的硬體或雲端運算成本。
• LLM-based Ranker 成本:
使用 gpt-4o-mini 進行 top-k 10 的重排評測,3493 題共花費 $2.66 美金。然而,若處理 top-k 50,單題 tokens 數可能達 22k,成本會顯著增加。
• 速度考量:ReRanker 的速度對於用戶體驗至關重要,數百毫秒的延遲通常可以接受,但超過 1 秒則不佳。
◦ Cohere API:速度最快,即使 k = 100 也能在約 600ms 內完成。
◦ Jina API:速度最慢,top-k 10 需 1 秒,top-k 100 需 2 秒,影響實用性。
◦ 開源模型:若無 GPU 部署,速度會太慢,不具實用性。
◦ LLM-based Ranker 速度:gpt-4o-mini 處理 top-k 10 大約每題 1 秒,但 top-k 50 則需 4 秒,實用性不高。
• 泛化能力與語義理解:
重排算法透過對查詢和文檔進行細粒度分析,能提升泛化能力並捕捉深層語義關係,更好地處理未見過的查詢或文檔。LLM-based Ranker 在語義理解和泛化能力上有潛力超越傳統 Cross-Encoder 模型。
• 與 RAG 系統結合:
ReRank 算法在 RAG 系統中尤為關鍵,它確保輸入生成模型的文檔與查詢高度相關,從而大大提高生成答案的品質和相關性。重排也能將 MRR (倒數排名) 大幅提升到接近命中率,這表示許多正確答案被排到第一位,有助於後續 LLM 的生成。
• 節省 LLM tokens 成本:
透過 ReRanker 重排後,可以更精確地選擇 top 3 或 top 5 文件作為 LLM 的上下文,有效節省 RAG 耗費的 tokens 量。
• 輸入長度限制:
不同 ReRanker 模型有不同的輸入長度限制 (查詢 + 文檔 chunk 的總 tokens 數)。Voyage 支援到 8000 tokens,Cohere 支援 4096 tokens (會自動拆分),Jina 支援 1024 tokens (也會拆分),bge-reranker-base/large 則為 512 tokens。
• 中文模型選擇有限:
目前市場上專為中文設計的 ReRanker 模型選擇相對較少,主要為 Voyage、Cohere、Jina 和開源的 bge 系列。不支援中文的 ReRanker 模型(如 cross-encoder/ms-marco-MiniLM-L-6-v2)在中文環境下表現不佳,甚至會隨著 top-k 增加而性能下降。
• 應用場景考量:
◦ 大量文件但查詢量少 (如企業內部):
適合使用便宜的 Embedding 模型(如 OpenAI text-embedding-3-small),搭配 top-k 100 的重排器 (Cohere 或 Voyage) 來重排取前 3-5 筆,將成本花在後期查詢階段。
◦ 文件不多但查詢量大 (如 B2C 場景):
適合使用高級的 Embedding 模型(如 voyage-multilingual-2),ReRanker 可選擇較低配或縮小 top-k 以節省成本。
總結來說,在繁體中文環境下,現有的 ReRank 模型可以顯著提升資訊檢索的準確率,對於 RAG 系統尤其關鍵。然而,其成本通常高於單純的 Embedding 模型,且速度表現不一。實用性方面,選擇合適的 ReRanker 需要權衡準確率、延遲、成本、模型的輸入長度限制以及部署方式(API 或自部署 GPU)。對於中文環境,可用的模型選項較少,但仍有如 Voyage、Cohere、Jina 和 bge 系列等表現不錯的模型可供選擇。LLM-based Ranker 具有潛力,但在成本、速度和穩定性方面仍有挑戰。
相關文章來源1:https://developer.volcengine.com/articles/7389112197621743657
相關文章來源2:https://ihower.tw/blog/12227-reranker


 iThome鐵人賽
iThome鐵人賽